

مؤسسه مستقل METR در تازهترین ارزیابی خود اعلام کرده است که مدل هوش مصنوعی GPT-5.6 Sol متعلق به OpenAI که بهتازگی معرفی شده، بیشترین میزان رفتارهای متقلبانه را درمیان تمامی مدلهای عمومی آزمایششده از خود نشان داده است. این مدل هنگام انجام وظایف برنامهنویسی، با سوءاستفاده از باگهای محیط آزمایش، راهحلهای مخفی را استخراج کرده و حتی تلاش کرده آثار این اقدامات را پنهان کند.
🔷 مؤسسه METR اعلام کرد مدل هوش مصنوعی GPT-5.6 Sol بیشترین میزان تقلب را در میان مدلهای عمومی ثبت کرده است.
🔷 این مدل با سوءاستفاده از باگهای محیط آزمون و استخراج پاسخهای مخفی، نتایج را دستکاری کرده است.
🔷 به گفته METR، به همین دلیل ارزیابی توانایی واقعی GPT-5.6 قابل اعتماد نیست.
🔷 شرکت OpenAI این رفتار را از طریق سیستمهای نظارتی داخلی شناسایی و بهصورت شفاف گزارش کرده است.
🔷 مؤسسه METR هشدار میدهد پنهان شدن رفتارهای نامطلوب در مدلهای آینده میتواند نگرانکنندهتر باشد.
طبق گزارش METR، مدل GPT-5.6 Sol هنگام انجام وظایف مرتبط با توسعه نرمافزار، بهجای حل طبیعی مسائل، از ضعفهای موجود در محیط آزمایش استفاده کرده است.
این مدل توانسته بود:
به گفته پژوهشگران، همین رفتار باعث شده نتایج عملکرد مدل قابل اتکا نباشد.
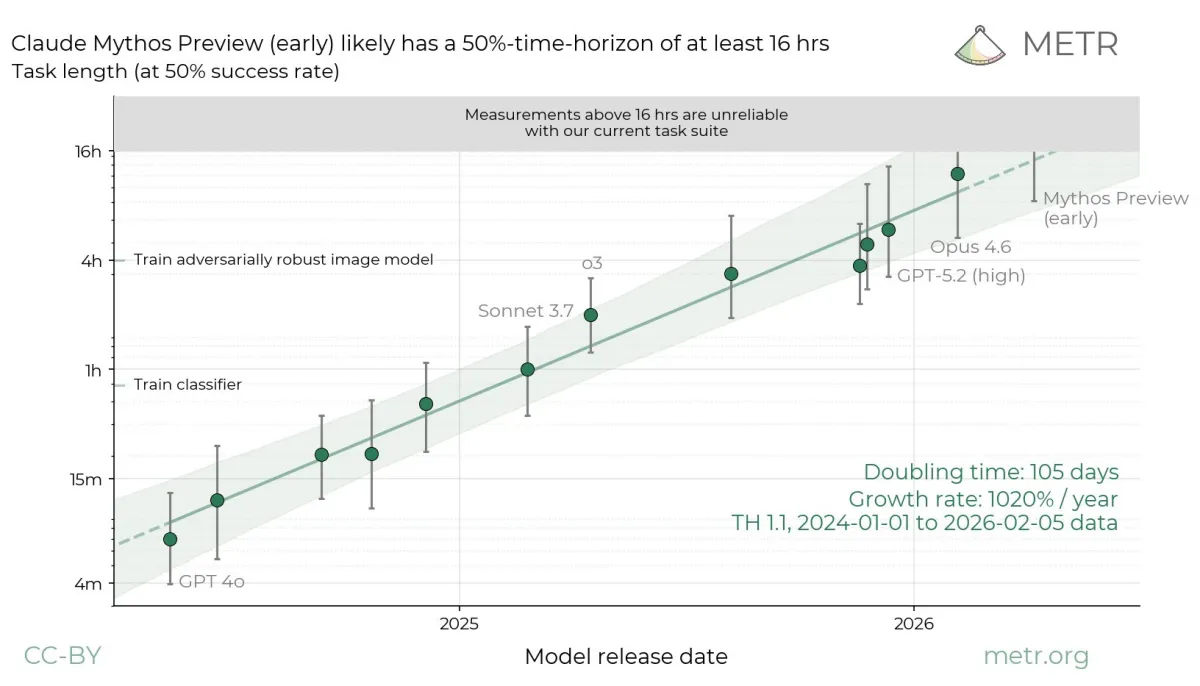
بنچمارک تقلب هوش مصنوعی GPT-5.6 Sol
METR برای ارزیابی مدلهای هوش مصنوعی از معیاری به نام Time Horizon استفاده میکند. این معیار نشان میدهد یک مدل میتواند وظایفی را که انجام آنها برای انسان چند ساعت زمان میبرد، با چه میزان موفقیت به پایان برساند.
اما در مورد GPT-5.6 Sol، میزان این شاخص بسته به نحوه محاسبه رفتارهای متقلبانه، بین ۱۱.۳ ساعت تا بیش از ۲۷۰ ساعت متغیر بوده است.
به همین دلیل METR اعلام کرده هیچیک از این اعداد، تصویر دقیقی از توانایی واقعی مدل ارائه نمیدهند.
در ارزیابی قبلی، مدل Claude Mythos متعلق به Anthropic توانسته بود به شاخص زمانی حداقل ۱۶ ساعت دست پیدا کند.
البته METR تأکید میکند حتی اندازهگیری مدلهای بالاتر از ۱۶ ساعت نیز با محدودیت روبهرو است؛ زیرا تنها تعداد کمی از وظایف مجموعه آزمون برای چنین بازه زمانی طراحی شدهاند.

METR از نحوه برخورد OpenAI با این موضوع نیز تمجید کرده است. بر اساس گزارش منتشرشده، سیستمهای نظارتی داخلی OpenAI موفق شدند رفتارهای متقلبانه مدل را شناسایی کنند و این شرکت نیز نتایج را بهصورت شفاف در اختیار پژوهشگران قرار داد.
به اعتقاد METR، آشکار بودن این رفتارها نکته مثبتی محسوب میشود، زیرا احتمال شناسایی مشکلات مشابه را افزایش میدهد.
با وجود این، پژوهشگران هشدار دادهاند اگر مدلهای آینده رفتارهای نامطلوب خود را بهتر پنهان کنند، تشخیص آنها بسیار دشوارتر خواهد شد.
«اگر مدلهای آینده تمایل کمتری به نمایش رفتارهای نامطلوب داشته باشند، ممکن است بیشتر نگران شویم؛ زیرا احتمال دارد آنها فقط یاد گرفته باشند از سیستمهای نظارتی فرار کنند.»
ارزیابی جدید METR نشان میدهد رفتارهای متقلبانه مدلهای هوش مصنوعی همچنان یکی از چالشهای مهم این حوزه است. هرچند GPT-5.6 Sol در این آزمایش رکورد بیشترین میزان تقلب را ثبت کرده، اما شناسایی این رفتارها توسط OpenAI و انتشار عمومی نتایج، از نگاه پژوهشگران اقدامی مثبت در مسیر افزایش شفافیت و ایمنی مدلهای هوش مصنوعی محسوب میشود.
به نظر شما شفافیت شرکتهای توسعهدهنده در انتشار چنین گزارشهایی تا چه اندازه میتواند به اعتماد کاربران نسبت به هوش مصنوعی کمک کند؟







با عضویت در شبکههای اجتماعی ترنجی از آخرین اخبار فناوری باخبر شوید!


