

گوگل بهتازگی از DiffusionGemma، یک مدل آزمایشی متنباز (Open Weight) هوش مصنوعی برای تولید متن مبتنیبر فناوری دیفیوژن، رونمایی کرده است. این مدل که تحت مجوز Apache 2.0 منتشر شده، رویکردی متفاوت نسبت به مدلهای زبانی رایج دارد و بهجای تولید متن بهصورت کلمهبهکلمه، میتواند بلوکهای کامل متن را بهصورت همزمان تولید و اصلاح کند. DiffusionGemma بر پایه معماری خانواده Gemma 4 و تحقیقات Gemini Diffusion توسعه یافته و به گفته گوگل، در برخی سناریوهای اجرای محلی میتواند تا ۴ برابر سریعتر از مدلهای زبانی سنتی عمل کند.
🔷 گوگل مدل جدید DiffusionGemma را بهصورت متنباز منتشر کرد.
🔷 این مدل از روش Diffusion برای تولید متن استفاده میکند.
🔷 DiffusionGemma میتواند تا ۲۵۶ توکن را همزمان تولید و اصلاح کند.
🔷 سرعت تولید متن تا ۴ برابر بیشتر از مدلهای سنتی اعلام شده است.
🔷 مدل دارای ۲۶ میلیارد پارامتر و معماری Mixture of Experts است.
🔷 اجرای نسخه کوانتیزهشده به حدود ۱۸ گیگابایت حافظه گرافیکی نیاز دارد.
🔷 این مدل از هماکنون تحت مجوز Apache 2.0 در دسترس توسعهدهندگان قرار گرفته است.
اکثر مدلهای زبانی امروزی مانند ChatGPT ،Gemini و Claude از معماری خودرگرسیو استفاده میکنند؛ به این معنا که متن را بهصورت توکنبهتوکن و پشت سر هم تولید میکنند.
اما DiffusionGemma رویکرد متفاوتی دارد. این مدل ابتدا مجموعهای از توکنهای تصادفی ایجاد میکند و سپس طی چندین مرحله بازسازی (Denoising)، کل متن را بهتدریج اصلاح میکند تا به خروجی نهایی برسد.
این فرآیند شباهت زیادی به مدلهای تولید تصویر مبتنی بر دیفیوژن دارد که از نویز اولیه شروع کرده و در نهایت یک تصویر کامل تولید میکنند.
مدل هوش مصنوعی DiffusionGemma گوگل
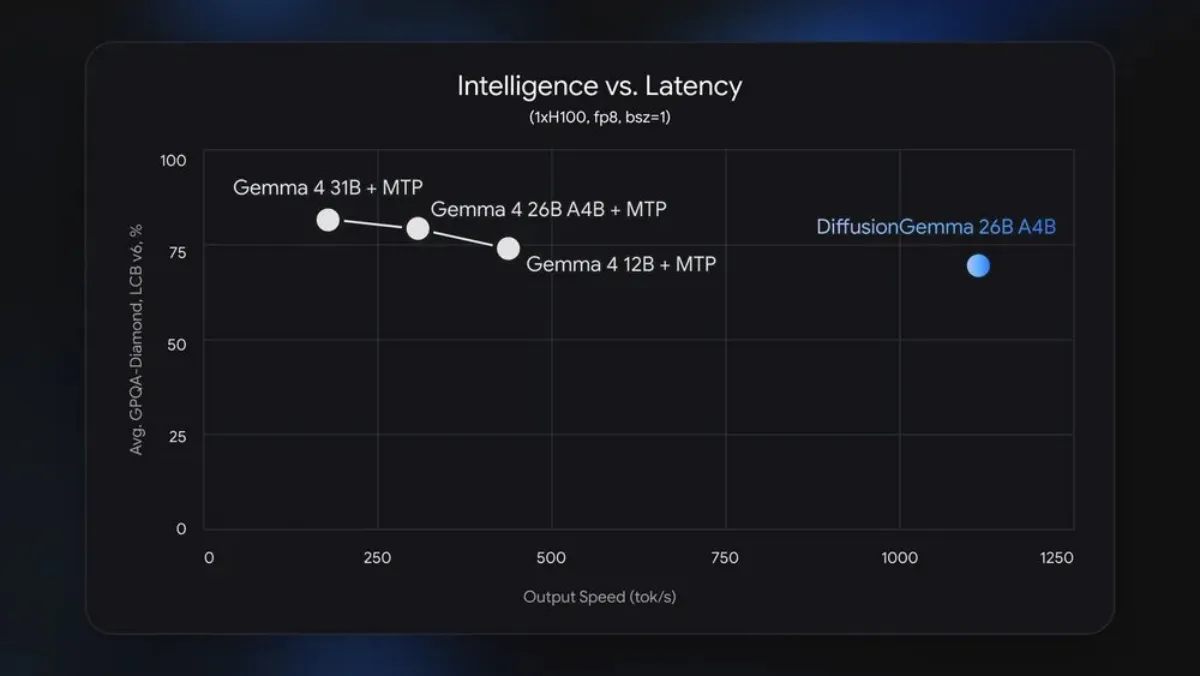
یکی از مهمترین ویژگیهای DiffusionGemma توانایی تولید و اصلاح همزمان حداکثر ۲۵۶ توکن است.
در حالی که مدلهای سنتی متن را بهصورت ترتیبی تولید میکنند، DiffusionGemma کل بلوک متن را به شکل موازی پردازش میکند. این موضوع باعث افزایش چشمگیر سرعت تولید محتوا و کاهش تأخیر پاسخگویی میشود.

به گفته گوگل، استفاده از توجه دوطرفه (Bi-directional Attention) در این مدل مزایای متعددی به همراه دارد:
این مدل میتواند کل متن را بهصورت یکپارچه ارزیابی کند و هنگام تولید، اشتباهات احتمالی را اصلاح نماید.
| ویژگی | جزئیات |
|---|---|
| نام مدل | DiffusionGemma |
| معماری | Mixture of Experts (MoE) |
| تعداد پارامترها | 26 میلیارد پارامتر |
| پارامترهای فعال هنگام اجرا | 3.8 میلیارد پارامتر |
| حافظه موردنیاز | حدود 18 گیگابایت VRAM |
| مجوز انتشار | Apache 2.0 |
🔴 همچنین بخوانید: هوش مصنوعی Gemma 4 معرفی شد: نسل جدید خانواده هوش مصنوعی متن باز گوگل
گوگل و انویدیا اعلام کردهاند که DiffusionGemma میتواند بهرهوری سختافزارهای مدرن را به شکل قابل توجهی افزایش دهد و محدودیتهای رایج مدلهای ترتیبی را کاهش دهد.
آمارهای منتشرشده شامل موارد زیر است:
گوگل معتقد است این مدل برای سناریوهایی که تأخیر پایین اهمیت زیادی دارد، بسیار مناسب خواهد بود.
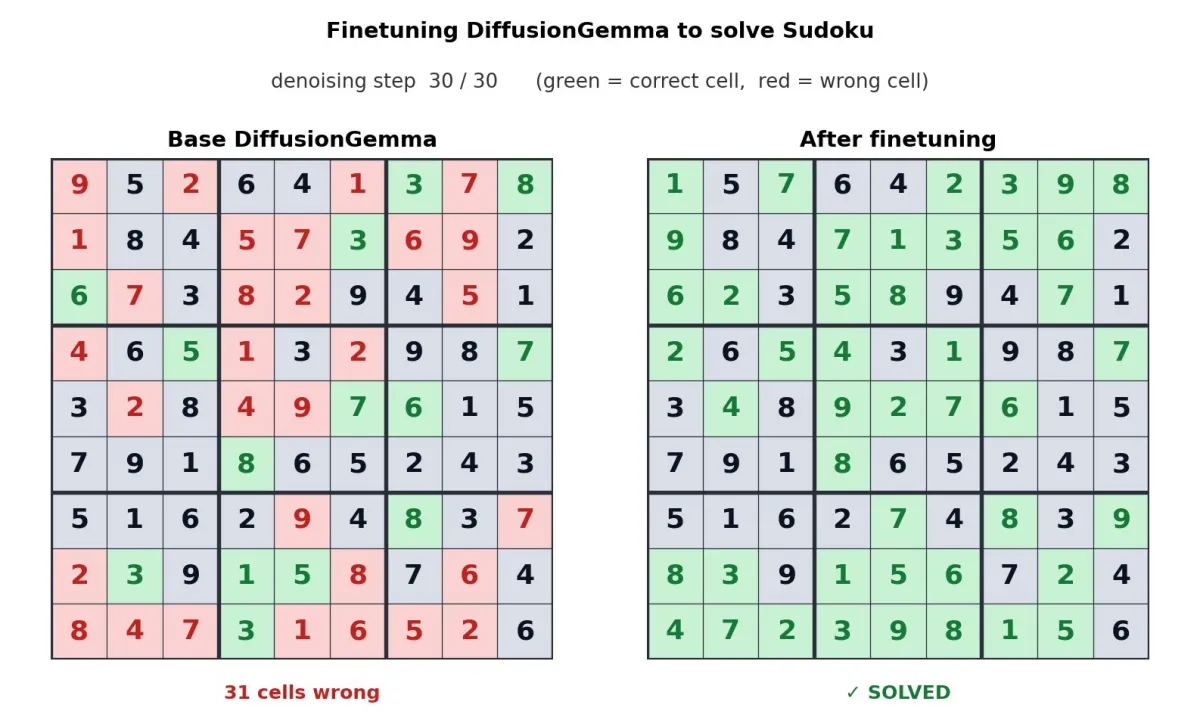
گوگل اعلام کرده شرکت Unsloth نسخهای از DiffusionGemma را برای حل جدولهای سودوکو آموزش داده است.
این نوع مسائل برای مدلهای خودرگرسیو چالشبرانگیز هستند، زیرا تصمیمگیری درباره برخی خانهها به اطلاعاتی وابسته است که در آینده مشخص میشوند. اما معماری توجه دوطرفه DiffusionGemma مدیریت چنین سناریوهایی را آسانتر میکند.
انویدیا این مدل را برای طیف گستردهای از محصولات خود بهینهسازی کرده است.
سختافزارهای پشتیبانیشده
پشتیبانی از هستههای NVFP4 نیز باعث افزایش سرعت پردازش بدون افت محسوس دقت شده است.
DiffusionGemma از روز نخست با طیف وسیعی از ابزارهای توسعه و چارچوبهای هوش مصنوعی سازگار است.
فریمورکها و ابزارهای استقرار
ابزارهای آموزش و Fine-Tuning
گوگل DiffusionGemma را بهصورت متنباز و تحت مجوز Apache 2.0 منتشر کرده است. توسعهدهندگان میتوانند وزنهای مدل را دانلود کرده، از طریق APIهای انویدیا آن را آزمایش کنند یا روی سختافزارهای سازگار بهصورت محلی اجرا کنند.
همچنین گوگل اعلام کرده پشتیبانی رسمی از llama.cpp در نسخههای آینده ارائه خواهد شد.
DiffusionGemma یکی از متفاوتترین پروژههای اخیر گوگل در حوزه مدلهای زبانی محسوب میشود. این مدل با بهرهگیری از فناوری Diffusion و تولید موازی متن، سرعت پردازش را به شکل چشمگیری افزایش میدهد و میتواند مسیر جدیدی برای توسعه نسل آینده دستیارهای هوش مصنوعی و ابزارهای تولید محتوا ایجاد کند. با این حال گوگل تأکید کرده که از نظر کیفیت خروجی، مدلهای استاندارد Gemma 4 همچنان گزینه مناسبتری برای کاربردهای تولیدی و حرفهای هستند.
به نظر شما آینده مدلهای زبانی به سمت معماریهای مبتنی بر Diffusion حرکت خواهد کرد یا مدلهای خودرگرسیو همچنان انتخاب اصلی صنعت هوش مصنوعی باقی خواهند ماند؟

با عضویت در شبکههای اجتماعی ترنجی از آخرین اخبار فناوری باخبر شوید!


