



شرکت علیبابا (Alibaba) مدل جدید Qwen3.5 را بهعنوان اولین عضو از سری مدلهای جدید هوش مصنوعی خود منتشر کرده است. این مدل که در یک معماری واحد قادر به پردازش متن، تصویر و ویدیو است، بهصورت رایگان و با وزنهای باز (Open-Weight) در دسترس عموم قرار گرفته است.
🔹مدل Qwen3.5 دارای ۳۹۷ میلیارد پارامتر است که تنها ۱۷ میلیارد آن در هر پردازش فعال میشود.
🔹سرعت پردازش این مدل تا ۱۹ برابر بیشتر از نسل قبلی خود یعنی Qwen3-Max است.
🔹عملکرد عالی در وظایف ایجنتی و درک تصویر، هرچند کمی پایینتر از GPT-5.2 و Claude 4.5 Opus.
🔹پشتیبانی از ۲۰۱ زبان و قابلیت اجرای مستقل وظایف روی رابط کاربری کامپیوتر و گوشی.
🔹این مدل با مجوز Apache 2.0 برای استفاده تجاری و تغییرات آزاد است.
این مدل دارای مجموعاً ۳۹۷ میلیارد پارامتر است، اما برای هر درخواست خاص تنها ۱۷ میلیارد پارامتر فعال میشود. مانند سایر مدلهای بزرگ هوش مصنوعی، این مدل نیز از معماری «ترکیب متخصصان» (Mixture-of-Experts) استفاده میکند که بسته به نوع وظیفه، تنها بخشهای مرتبط شبکه را فعال میسازد. نسبت پارامترهای کل به فعال در Qwen3.5 بهطور غیرمعمولی بالاست که نشاندهنده تقسیمبندی بسیار دقیق بین متخصصان مختلف است. علیبابا همچنین از معماری توجه جدیدی به نام Gated Delta Networks استفاده کرده است که هزینههای محاسباتی را بیشازپیش کاهش میدهد.
تیم توسعهدهنده میگوید که Qwen3.5 درخواستها را ۱۹ برابر سریعتر از سلف بسیار بزرگتر خود یعنی Qwen3-Max و ۳.۵ تا ۷ برابر سریعتر از نسل قبلی مستقیم خود یعنی Qwen3-235B (با پنجره زمینه ۲۵۶ هزار توکنی) پردازش میکند، درحالیکه سطح عملکرد حفظ شده است.

مدل Qwen3.5 در برخی بنچمارکها رکوردهای جدیدی ثبت کرده اما در برخی دیگر از GPT-5.2 ،Claude 4.5 Opus و Gemini-3 Pro عقب مانده است. بزرگترین پیشرفتها در وظایف ایجنتی (Agentic Tasks) دیده میشود:
علیبابا ادعا میکند که Qwen3.5 در چندین بنچمارک ریاضی-بصری از جمله MathVision (۸۸.۶) و ZEROBench (۱۲) نمرات برتر را کسب کرده است. همچنین در اکثر تستهای درک اسناد و تشخیص متن پیشتاز است. بااینحال، در بنچمارک گستردهتر درک تصویر MMMU، با امتیاز ۸۵ از Gemini 3 Pro (۸۷.۲) و GPT-5.2 (۸۶.۷) عقبتر است.
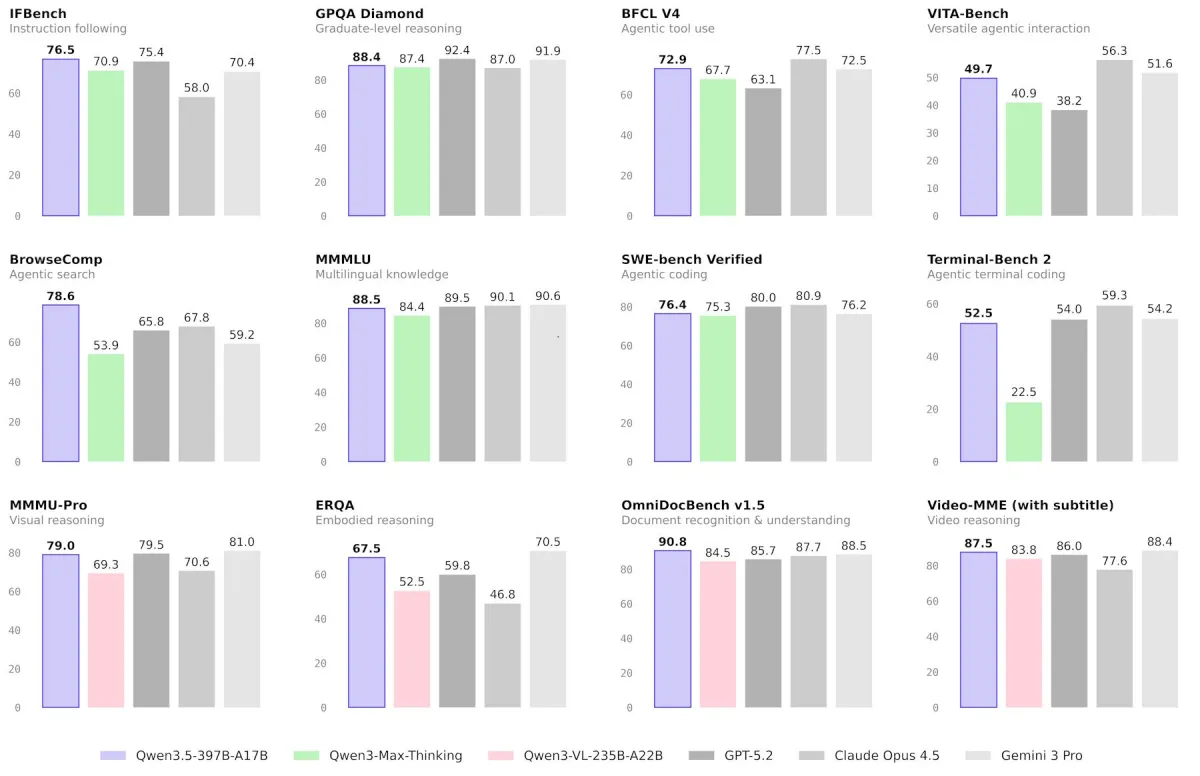
بنچمارک مدل هوش مصنوعی Qwen3.5
تیم سازنده جهش نسبتبه سری قبلی Qwen3 را مدیون فاز گسترده یادگیری تقویتی (Reinforcement Learning) در طول آموزش میداند. آنها بهجای بهینهسازی مدل برای بنچمارکهای فردی، تنوع و دشواری محیطهای آموزشی را بهطور سیستماتیک افزایش دادند. بیشترین دستاورد این رویکرد در مهارتهای ایجنتی نمایان شد.
علیبابا همچنین میگوید که این مدل با دادههای بسیار بیشتری نسبتبه نسل قبلی و با فیلترهای سختگیرانهتر آموزش دیده است. پشتیبانی زبانی از ۱۱۹ به ۲۰۱ زبان و گویش افزایش یافته و دایره واژگان به ۲۵۰ هزار توکن رسیده که سرعت پردازش را ۱۰ تا ۶۰ درصد بهبود میبخشد.
بهعنوان یک مدل چندوجهی بومی، Qwen3.5 میتواند تا دو ساعت ویدیو را پردازش کند. در دموهای منتشرشده، این مدل با نوشتن کد پایتون بهصورت مستقل یک ماز را حل کرده و کوتاهترین مسیر را ترسیم میکند. همچنین بهعنوان یک ایجنت رابط کاربری گرافیکی (GUI Agent)، میتواند بهطور مستقل با رابطهای گوشی هوشمند و کامپیوتر کار کند؛ مثلاً فرمهای اکسل را پر کند یا گردشکارهای چندمرحلهای دسکتاپ را اجرا نماید.
مدل وزنباز Qwen3.5-397B-A17B برای دانلود در Hugging Face موجود است و تحت مجوز Apache 2.0 عرضه میشود که اجازه استفاده تجاری را میدهد. نسخه میزبانیشده Qwen3.5-Plus با پنجره زمینه یک میلیون توکنی از طریق API استودیوی مدل ابری علیبابا در دسترس است.
هزینه استفاده از API این مدل ۰.۴۰ دلار به ازای هر میلیون توکن ورودی و ۲.۴۰ دلار به ازای هر میلیون توکن خروجی است؛ کسری از قیمتی که OpenAI یا Anthropic برای مدلهای مشابه دریافت میکنند.
بهنظر شما آیا قیمت پایین و عملکرد بالای مدلهای چینی مانند Qwen3.5 میتواند انحصار شرکتهای آمریکایی در بازار هوش مصنوعی را بشکند؟
