

شرکت آنتروپیک (Anthropic) از جدیدترین مدل هوش مصنوعی پرچمدار خود با نام Claude Opus 4.6 رونمایی کرد. این مدل که نسخه ارتقایافته Opus 4.5 محسوب میشود، برای اولینبار در سری Opus به یک پنجره متن (Context Window) عظیم یک میلیون توکنی مجهز شده است که درحالحاضر بهصورت نسخه بتا در دسترس قرار دارد. بهگفته سازندگان، این مدل قادر است اطلاعات مرتبط را در اسناد بسیار حجیم با قابلیت اطمینان بیشتری نسبتبه مدلهای قبلی پیدا کند.
🔹مدل هوش مصنوعی Claude Opus 4.6 با حافظه یک میلیون توکنی و قابلیت فشردهسازی محتوا معرفی شد.
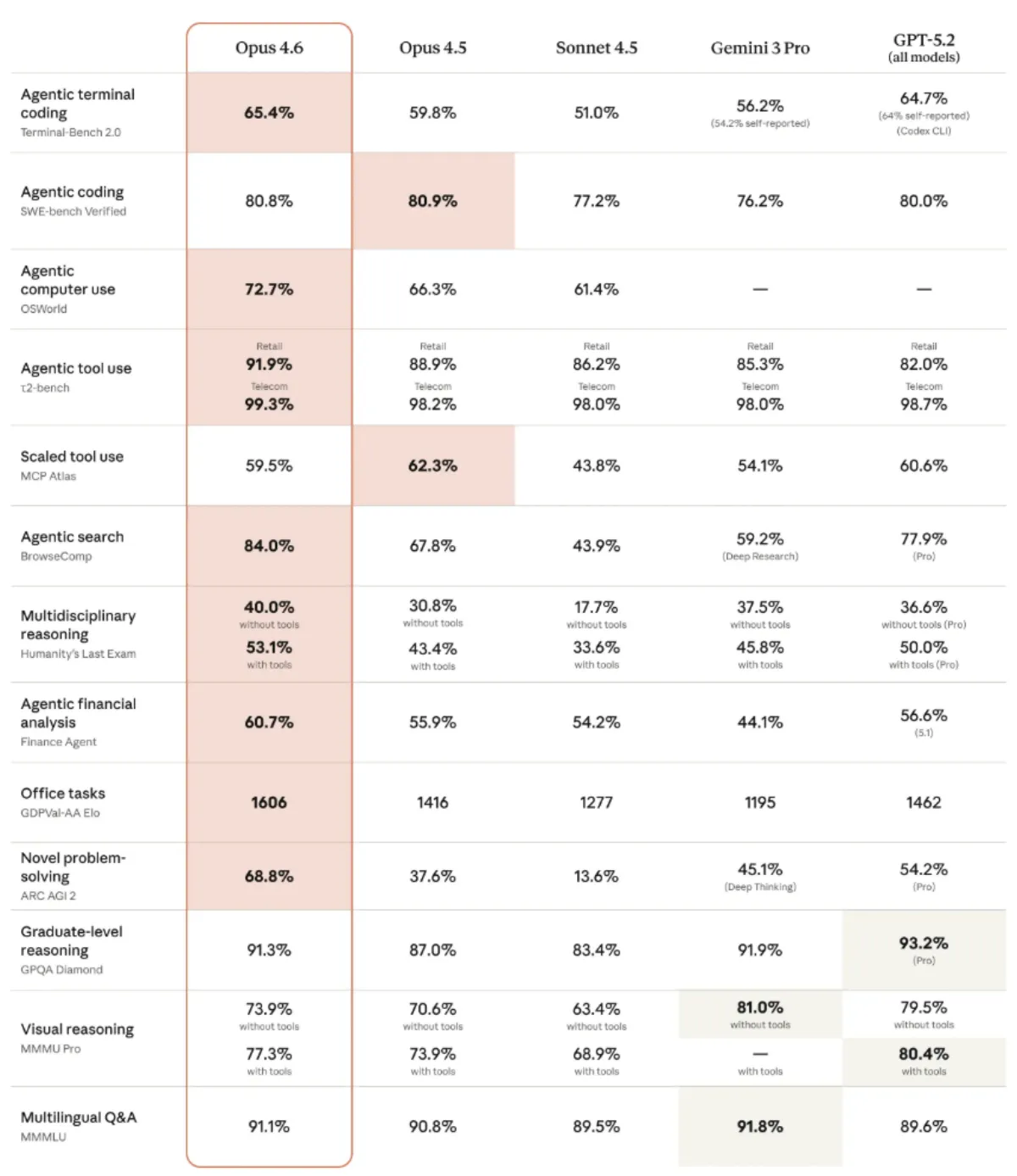
🔹این مدل در تستهای یافتن اطلاعات پنهان، امتیاز ۷۶ درصد را کسب کرد که بسیار بالاتر از رقباست.
🔹در بنچمارکهای کار دانشی و استدلال، این مدل از GPT-5.2 و Opus 4.5 پیشی گرفته است.
🔹قابلیتهای جدید شامل ادغام پیشرفته با اکسل، پاورپوینت و تیمهای ایجنت در کدنویسی است.
🔹هزینه استفاده برای پرامپتهای طولانی (بیش از ۲۰۰ هزار توکن) دو برابر نرخ استاندارد است.
افزایش پنجره متن معمولاً با مشکلی شناختهشده به نام «فرسایش محتوا» (Context Rot) همراه است؛ به این معنا که هرچه اطلاعات ورودی برای پردازش بیشتر باشد، عملکرد مدل کاهش مییابد. آنتروپیک اعلام کرده که این چالش را از طریق بهبود خودِ مدل و ویژگی جدیدی به نام Compaction (فشردهسازی) حل کرده است. این ویژگی قبل از پر شدن پنجره، بهطور خودکار محتویات قدیمیتر را خلاصه میکند.
در تست MRCR v2 که توانایی مدلها در یافتن اطلاعات مخفیشده در حجم زیادی از متن را میسنجد، Opus 4.6 با یک میلیون توکن موفق به کسب امتیاز ۷۶ درصد شد. این درحالی است که مدل کوچکتر Sonnet 4.5 در شرایط مشابه تنها ۱۸.۵ درصد امتیاز کسب کرد.
در بنچمارک GDPval-AA که کار دانشی را در حوزههایی مانند مالی و حقوقی آزمایش میکند، Opus 4.6 به امتیاز Elo برابر با ۱۶۰۶ دست یافت. این نمره ۱۴۴ امتیاز بالاتر از مدل GPT-5.2 شرکت OpenAI (با امتیاز ۱۴۶۲) و ۱۹۰ امتیاز بیشتر از Opus 4.5 (با امتیاز ۱۴۱۶) است.
همچنین در تست استدلال چندرشتهای Humanity’s Last Exam، این مدل با استفاده از ابزارها امتیاز ۵۳.۱ درصد را کسب کرد و از تمام رقبا پیشی گرفت. در بنچمارک کدنویسی مبتنیبر ایجنت Terminal-Bench 2.0 نیز این مدل به امتیاز ۶۵.۴ درصد دست یافت.
بااینحال، آنتروپیک اشاره کرده که این مدل تمایل دارد روی کارهای ساده بیشازحد فکر کند (Overthinking). این موضوع باعث میشود مدل نتیجهگیریهای خود را مکرراً بررسی کند که منجر به هزینههای بالاتر و زمان پاسخگویی طولانیتر برای پرسشهای ساده میشود. برای کارهای سادهتر، پیشنهاد میشود پارامتر تلاش (Effort) از حالت «زیاد» به «متوسط» تغییر داده شود.
مدل هوش مصنوعی Claude Opus 4.6
این مدل هماکنون در پلتفرم claude.ai و از طریق API در دسترس است. قیمتگذاری استاندارد برای ورودی ۵ دلار و برای خروجی ۲۵ دلار به ازای هر میلیون توکن است. اما برای پرامپتهایی که طول آنها بیش از ۲۰۰,۰۰۰ توکن باشد، نرخهای پریمیوم اعمال میشود.
| نوع سرویس | قیمت ورودی (بهازای ۱ میلیون توکن) | قیمت خروجی (بهازای ۱ میلیون توکن) |
|---|---|---|
| استاندارد (زیر ۲۰۰ هزار توکن) | ۵ دلار | ۲۵ دلار |
| پریمیوم (بالای ۲۰۰ هزار توکن) | ۱۰ دلار | ۳۷.۵۰ دلار |
آنتروپیک چندین ویژگی جدید به API خود اضافه کرده است. قابلیت «تفکر تطبیقی» (Adaptive Thinking) به مدل اجازه میدهد تصمیم بگیرد چه زمانی به استدلال عمیقتر نیاز دارد. حداکثر خروجی مدل اکنون به ۱۲۸,۰۰۰ توکن رسیده است. همچنین در بخش Claude Code، کاربران میتوانند از «تیمهای ایجنت» (Agent Teams) استفاده کنند که در آن چندین ایجنت هوش مصنوعی بهصورت موازی روی وظایف کار میکنند.
برای کاربران اداری، ادغام با اکسل بهروزرسانی شده و پیشنمایش تحقیقاتی برای ادغام با پاورپوینت عرضه شده است. در اکسل، کلود اکنون میتواند دادههای بدون ساختار را پردازش کرده، ساختار صحیح را تعیین کند و تغییرات چندسطحی را در یک مرحله انجام دهد.
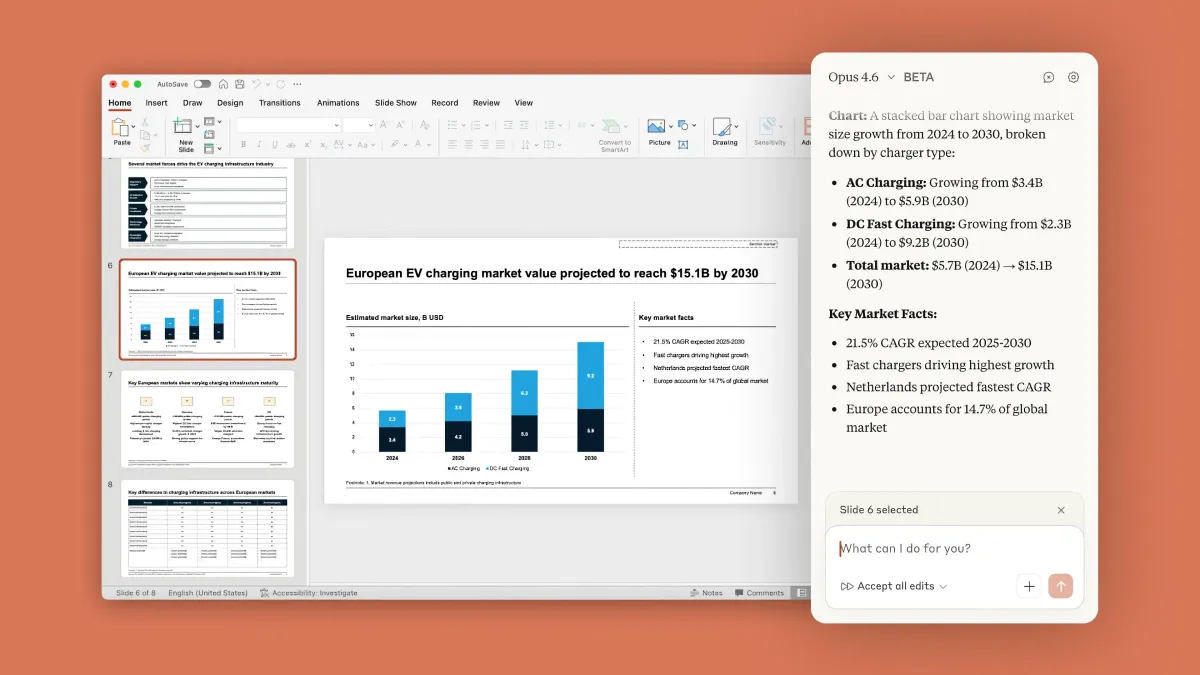
ادغام با پاورپوینت
با وجود پیشرفتهای عملکردی، Opus 4.6 در برابر حملات «تزریق پرامپت غیرمستقیم» (Indirect Prompt Injection) کمی آسیبپذیرتر از نسل قبلی خود است که این موضوع بهویژه برای کاربردهای ایجنتمحور نگرانکننده است. نکته قابلتوجه این است که آنتروپیک دیگر نتایج مربوط به تزریق پرامپت مستقیم را گزارش نمیکند؛ شاخصی که Opus 4.5 در آن بهترین عملکرد را داشت. این شرکت دلیل حذف این معیار را تمرکز بر تهدیدات شخص ثالث اعلام کرده است.
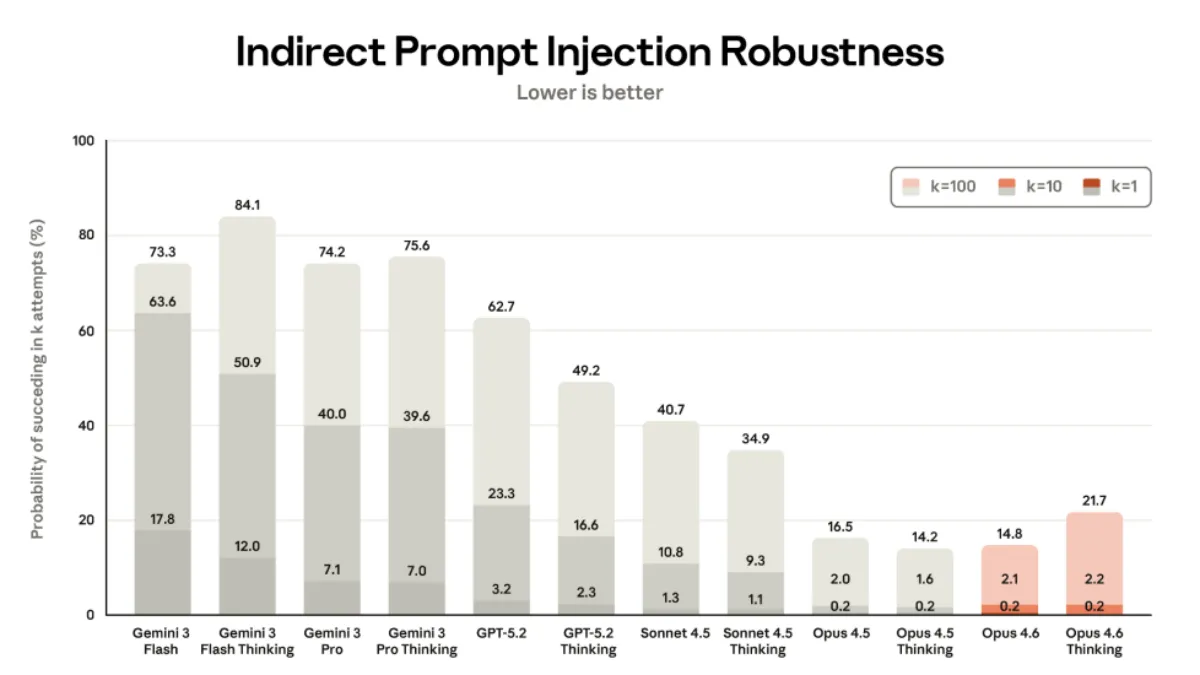
بهنظر شما آیا قابلیتهای پیشرفته استدلال و حافظه عظیم Claude Opus 4.6 ارزش هزینههای بالاتر آن نسبتبه مدلهای استاندارد را دارد؟