




هوش مصنوعی چینی Kimi K2 Thinking
مدل جدید Kimi K2 Thinking، که توسط استارتاپ چینی Moonshot AI منتشر شده، از معماری Mixture-of-Experts (MoE) بهره میبرد. این مدل با حدود یک تریلیون پارامتر کلی ساخته شده که تنها 32 میلیارد پارامتر آن در هر مرحله استنتاج (Inference) فعال میشود. این ساختار نه تنها قدرت محاسباتی بالا را تضمین میکند، بلکه کارایی مصرف انرژی را نیز به شدت افزایش میدهد.
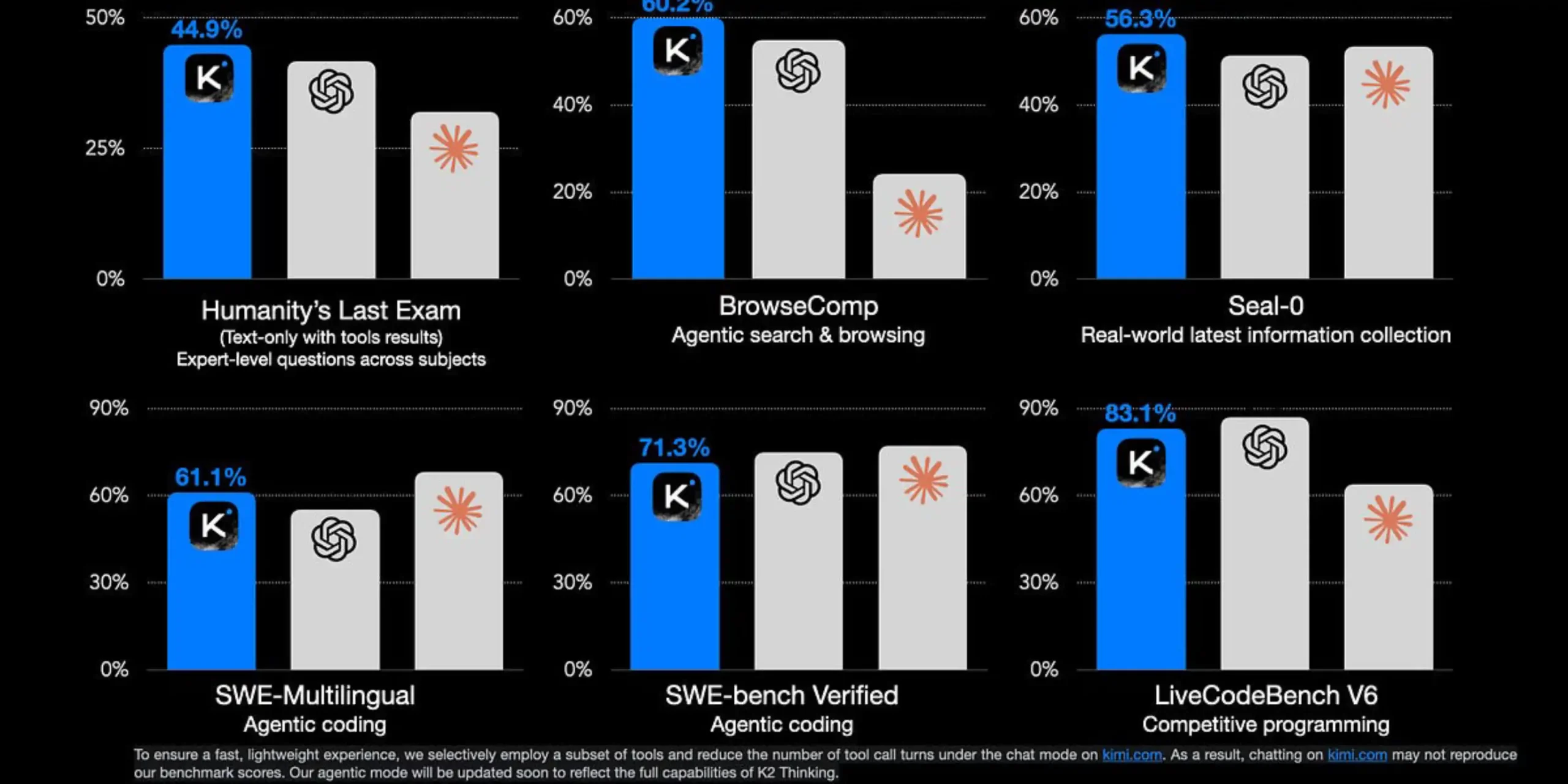
بر اساس نتایج منتشر شده توسط Moonshot، K2 Thinking در ارزیابیهای مهمی که نشاندهنده تواناییهای استدلال، کدنویسی و عملکرد عاملمحور (Agentic) هستند، از امتیازات متناظر GPT-5 پیشی گرفته است:
| بنچمارک (وظیفه) | Kimi K2 Thinking | GPT-5 | Claude Sonnet 4.5 |
|---|---|---|---|
| HLE (آزمون استدلال پیشرفته) | 44.9% | 41.7% | 32% |
| BrowseComp (جستجوی وب عاملمحور) | 60.2% | 54.9% | 24.1% |
| SWE-Bench Verified (کدنویسی/رفع باگ) | 71.3% | 74.9% | 77.2% |
| GPQA Diamond (پرسش و پاسخ با کیفیت) | 85.7% | 84.5% | — |
این نتایج نشاندهنده آن است که مدل متنباز K2 Thinking نه تنها به قابلیتهای مدلهای اختصاصی مانند GPT-5 و Claude Sonnet 4.5 رسیده، بلکه در بسیاری از زمینههای استدلال عاملمحور، از آنها فراتر رفته است.
Kimi K2 Thinking با هدف بهینهسازی کارایی و سرعت توسعه منتشر شده است. این مدل از ویژگیهای فنی برجستهای برخوردار است:
reasoning_content) میانی ارائه میدهد تا شفافیت در فرآیند منطقی حفظ شود.این مدل تحت یک لایسنس Modified MIT License در Hugging Face منتشر شده است. این لایسنس کاملترین حقوق تجاری و استفاده آزاد را میدهد، با این تفاوت که شرط زیر را اضافه میکند:
«اگر نرمافزار یا هر محصول مشتق شده از آن به بیش از 100 میلیون کاربر فعال ماهانه خدمات دهد یا بیش از 20 میلیون دلار آمریکا در ماه درآمد ایجاد کند، توسعهدهنده موظف است نام
Kimi K2را به صورت برجسته در رابط کاربری محصول نمایش دهد.»
این بند به عنوان یک شرط «انتساب سبک» عمل میکند و تقریباً تمام آزادیهای لایسنس استاندارد MIT را برای اکثر پژوهشگران و کاربردهای سازمانی حفظ میکند و آن را به یکی از آزادانهترین مدلهای پیشرو موجود تبدیل میکند.
سرعت پیشرفت مدلهای متنباز، از جمله MiniMax-M2 و اکنون Kimi K2 Thinking، نشاندهنده آن است که قابلیتهای هوش مصنوعی سطح بالا دیگر منحصر به مدلهای بسته و گرانقیمت سیلیکونولی نیست. این موضوع فشار فزایندهای را بر شرکتهای آمریکایی مانند OpenAI، مایکروسافت، متا و گوگل وارد میکند تا سرمایهگذاریهای تریلیون دلاری خود در زیرساختهای محاسباتی را توجیه کنند.
اگر یک مشتری سازمانی بتواند عملکرد مشابه یا بهتری را از یک مدل متنباز و رایگان چینی نسبت به راهکارهای اختصاصی و پولی مانند GPT-5 یا Claude Sonnet 4.5 به دست آورد، دلیل موجهی برای ادامه پرداخت هزینههای بالا وجود نخواهد داشت. این تحولات نشان میدهند که قابلیتهای پیشرفتهترین سیستمهای استدلالی ممکن است دیگر از شرکتهایی که مراکز داده غولپیکر میسازند به دست نیاید، بلکه از گروههای تحقیقاتی بهینهساز معماری و کوانتیزهسازی نشأت گیرد.
مدل Kimi K2 Thinking با پیشی گرفتن از GPT-5 در بسیاری از معیارهای استدلال و عاملمحور، یک تغییر ساختاری را در چشمانداز هوش مصنوعی رقم میزند. این مدل اثبات میکند که سیستمهای متنباز میتوانند در قابلیت و کارایی با مدلهای پیشرو اختصاصی رقابت کنند. برای جامعه پژوهشگران و شرکتها، این مدل شفافیت و قابلیت تعامل (Interoperability) بالایی را فراهم میآورد.
حال، این سوال مطرح است: با توجه به پیشرفت سریع مدلهای متنباز چینی و کارایی بالای آنها، آیا سازمان یا پروژه شما استفاده از مدلهای متنباز مانند Kimi K2 Thinking را به مدلهای اختصاصی و گرانقیمت غربی ترجیح خواهد داد؟ دلایل فنی و اقتصادی شما برای این انتخاب چیست؟ دیدگاه خود را با ما در بخش نظرات به اشتراک بگذارید.
