



پس از انتشار Gemini 1.0 در ماه دسامبر، گوگل بهتازگی Gemini 1.5 را بهعنوان مدل نسل بعدی هوش مصنوعی خود با عملکرد بسیار بهبودیافته معرفی کرده است.
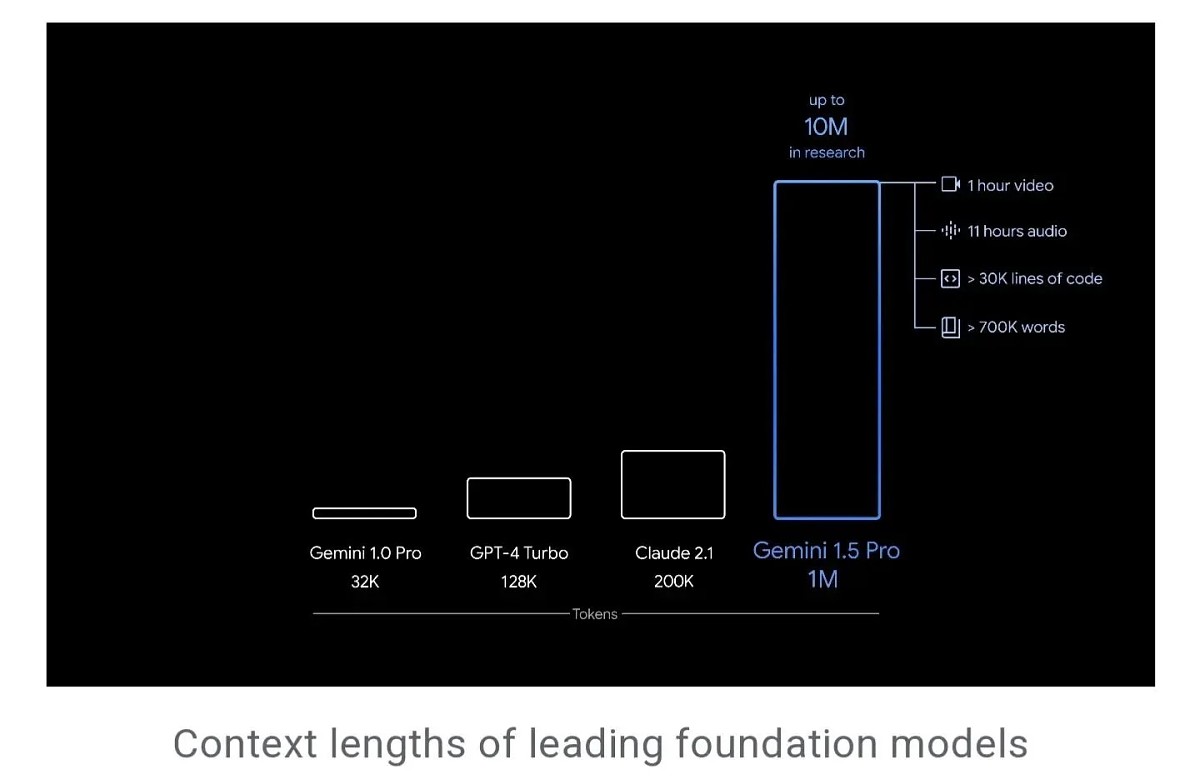
یکی از پیشرفتهای اصلی Gemini 1.5 یک پنجره زمینه بهطور قابلتوجهی بزرگتر است.
پنجره زمینه مدل جدید هوش مصنوعی از توکنها تشکیل شده است که بلوکهای ساختمانی مورداستفاده برای پردازش اطلاعات هستند. توکنها میتوانند تمام بخشها یا زیربخشهایی از کلمات، تصاویر، ویدیوها، صدا یا کد باشند. هرچه پنجره زمینه یک مدل بزرگتر باشد، اطلاعات بیشتری را میتواند در یک اعلان داده دریافت و پردازش کند و خروجی آن را سازگارتر، مرتبطتر و مفیدتر میکند.
Gemini 1.5 Pro دارای یک پنجره زمینه استاندارد با 128000 توکن (در مقابل 32000 توکن برای Gemini 1.0) است. این میزان به بیش از 700 هزار کلمه، پایگاه کد با بیش از 30 هزار خط کد، 11 ساعت صدا یا 1 ساعت ویدیو ترجمه میشود. GPT-4 Turbo نیز شامل 128 هزار توکن است و Claude 2.1 200 هزار توکن را ارائه میدهد. نمونههایی از این میزان توکن در عمل عبارتند از:
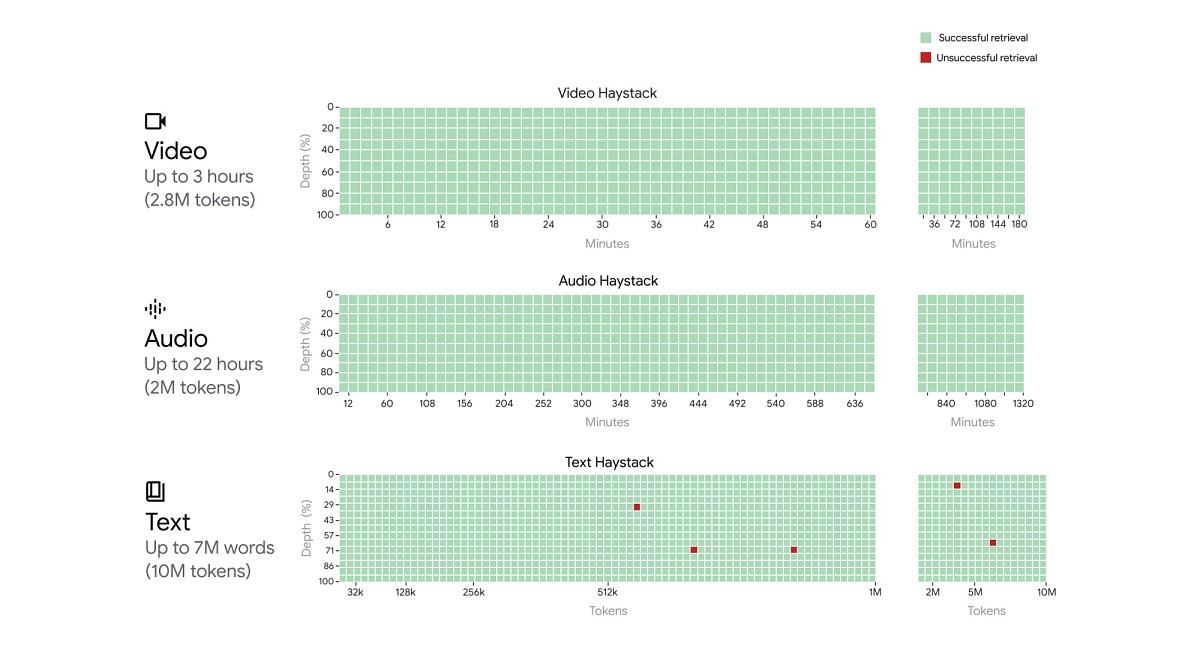
Gemini 1.5 Pro میتواند بهطور یکپارچه حجم زیادی از محتوا را در یک درخواست خاص تجزیهوتحلیل، طبقهبندی و خلاصه کند. برای مثال، وقتی رونوشتهای 402 صفحهای از مأموریت آپولو 11 به ماه داده میشود، میتواند درباره مکالمات، رویدادها و جزئیات موجود در سند استدلال کند.
Gemini 1.5 Pro میتواند وظایف بسیار پیچیدهای را برای درک و استدلال روشهای مختلف ازجمله ویدیو انجام دهد. بهعنوانمثال، زمانی که یک فیلم 44 دقیقهای بیصدا باستر کیتون به این مدل داده میشود، میتواند نقاط و رویدادهای مختلف داستان را بهدقت تحلیل کند و حتی درباره جزئیات کوچک فیلم که بهراحتی از دست میرود، استدلال کند.
Gemini 1.5 Pro میتواند وظایف حل مسئله مرتبطتری را در بلوکهای طولانیتر کد انجام دهد. هنگامی که درخواستی با بیش از 100 هزار خط کد به شما داده میشود، بهتر میتواند در بین مثالها استدلال کرده، تغییرات مفیدی را پیشنهاد کند و در مورد نحوه عملکرد بخشهای مختلف کد توضیحاتی ارائه دهد.
هوش مصنوعی Gemini 1.5 گوگل
قسمت قابلتوجه این است که گوگل تا 1 میلیون توکن تولید کرده است و آن را در اختیار برخی از آزمایشکنندگان اولیه قرار میدهد، درحالیکه همزمان تا 10 میلیون توکن متن را نیز با موفقیت آزمایش کرده است.
این پیشرفتها با معماری جدید Mixture-of-Experts (MoE) امکانپذیر میشوند که در آن مدلها «به شبکههای عصبی متخصص کوچکتر تقسیم میشوند. این باعث میشود Gemini 1.5 هم برای آموزش و هم برای سرویسدهی کارآمدتر باشد.
بسته به نوع ورودی دادهشده، مدلهای MoE یاد میگیرند که بهطور انتخابی فقط مرتبطترین مسیرهای خبره را در شبکه عصبی خود فعال کنند. این تخصص، کارایی مدل را بهشدت افزایش میدهد.
ازنظر عملکرد، Gemini 1.5 Pro نسبتبه Gemini 1.0 Pro در 87 درصد از معیارها در ارزیابیهای متن، کد، تصویر، صدا و ویدئو بهتر است. حتی در سطح گستردهای مشابه، نسخه 1.5 همسطح با 1.0 Ultra عمل میکند.
Gemini 1.5 Pro همچنین مهارتهای چشمگیر «یادگیری درونمتنی» را نشان میدهد، به این معنی که میتواند یک مهارت جدید را از اطلاعات دادهشده در یک اعلان طولانی، بدون نیاز به تنظیم دقیق اضافی بیاموزد.
Gemini 1.5 Pro (پنجره زمینه شامل 128 هزار توکن) بهعنوان یک پیشنمایش محدود برای توسعهدهندگان و مشتریان سازمانی از طریق AI Studio و Vertex AI در دسترس قرار میگیرد.
گوگل بیان کرده است که قصد دارد بهزودی با بهبود مدل، سطوح قیمتگذاری را معرفی کند که از پنجره متنی استاندارد 128 هزار توکن شروع میکند و تا 1 میلیون توکن افزایش مییابد.
نظر شما درباره هوش مصنوعی Gemini 1.5 گوگل چیست؟
