



گریزی چند بر معماری پاسکال:
از بحثهای همیشگی درباره انویدیا و ایام دی که گذر کنیم میرسیم به معماری پاسکال. معماری پاسکال تا حدود زیادی یک معماری بر پایه مکسول ۱ و مکسول ۲ انویدیا است. البته معماری پاسکال با معماری مکسول بسیار تفاوت دارد اما شالوده و سنگ بنای طراحی تا حدودی به هم نزدیک است. اما پاسکال حرفهای بسیاری برای گفتن دارد.
مهمترین تغییرات معماری پاسکال نسبت به مکسول ۲ تغییر حافظه موقت گرافیکی به HBM 2 و استفاده از رابط NVLink بود. حال برای اینکه تراشه GP100 محفل گردهمایی تمامی ویژگیهای پاسکال است مبنا را تراشه GP100 در نظر گرفته و با گوشه چشمی نسبت به ۱۰۶۰ متن را ادامه میدهیم.

تا سال گذشته انویدیا و تمام رقبا و در کل تمامی شرکتهای صنعت نیمهرسانا چندان تمرکزی بر عملکرد خودمختار و شبکهای تراشههایشان نداشتند اما امسال انویدیا پاسکال را با تمرکز ویژهای بر تشابه بر شبکهٔ مغزی انسان و هوش مصنوعی عرضه کرد. برای خودمختار بودن یک شبکهٔ عصبی مبتنی بر ترانزیستور فاکتوری به نام Front End مطرح میشود. هرچقدر مقدار این فاکتور بیشتر باید بدین معناست که واپایشگرهای یک مجموعه از ترانزیستورها (حال در پاسکال مجموعهای از هستههای چندکاره پردازشی انویدیا یا CUDA) خودمختاری بیشتری دارد و برای هر دستوری مستقیماً وابسته به CU و یا CPU برای تعیین بار پردازشی هر هسته (یا زیر هسته، SMX، SMM و یا SMP موجود در پاسکال) نیازمند نیست. اما این تنها مورد انتظار رفته نیست و میتوان از تراشههایی که از معماری پاسکال انویدیا استفاده میکنند و این قابلیت در آنها گمارده شده است انتظار هوش مصنوعی داشت.

اما FE) Front End) محاسبهای تا حدودی دقیق دارد و با داشتن تمام اطلاعات ریز یک تراشه میتوان تمایل آن به FE و CC) Core Count) را به دست آورد. در شکل زیر چندی از معماریهای بزرگ دنیا را میبینیم که برحسب FE و CC مرتب شدهاند. شایان ذکر است که معماری هرچقدر نزدیک به سمت چپ تصویر باشد بهاصطلاح CPU محورتر است (CPU محور بودن بدان معناست که پردازندهٔ گرافیکی مقدار بیشتری تشابه ساختاریِ کلی به CPU دارد و به طبع این موضوع خودمختارتر است، قدرت خام پردازش گرافیکی کمتر و تعداد واحد پردازشهای محاسبه و منطق و کلاسترها کمتر است) و معماری هر چه قدر به سمت راست نزدیکتر باشد تعداد واحدهای پردازشی منطقی و کلاسترها بیشتر است و بدین ترتیب قدرت محاسباتی خام بالاتر و خودمختاری تراشه کمتر.

NVLink جانشینی بلامنازع PCIe 3.0:
پی سی آی اکسپرس را به یاد دارید؟ رابط اصلی میان کارت گرافیک و پردازنده اصلی و ضعف مهمِ SLI. هر یک از پلهای پی سی آی اکسپرس با ۱۶ کانال میتواند پهنای باندی در حدود ۱۶ گیگابیت بر ثانیه به ارمغان آورند اما اکنون NVLink انویدیا توانسته با یک کانال به پهنای باندی برابر با ۴۰ گیگابیت بر ثانیه برسد که بهترین خبر برای دوستداران مجتمع کردن چند کارت گرافیک با یکدیگر است; این رابط جدید میتوانید رابطهای SLI بین دو کارت گرافیک را تا حدود ۸۰ گیگابایت بر ثانیه (با استفاده از دو پل SLI با اینترفیس جدید بر روی دو کارت گرافیک) برساند که میتواند تأخیرهای حاصل از کندی رابط پی سی آی اکسپرس نسل سومی را بگیرد. البته این بدین معنا نیست که واصلِ پی سی آی اکسپرس نسل سومی کند است; بههیچوجه! اما NVLink بسیار پرسرعتتر از پی سی آی اکسپرس است.

البته یکی دیگر از بهبودهای این اینترفیس جدید بهبود ارتباط بین پردازنده اصلی و کارت گرافیک تا ۱۰ برابر است که البته این مورد چندان دستیافتنی نیست. تفاوت دیگر NVLink با پی سی آی اکسپرس نسل سومی تعداد کانال و درگاه ارتباطی است; در NVLink شاهد یک پروتکل جدیدی به نام Point to Point هستیم و این به این معناست که یک واسط SLI با اینترفیس NVLink میتواند بااتصال همزمان حداکثر به ۷ کارت گرافیک (درمجموع ۸ کارت) و با ۲ یا ۱ پل SLI با یک گرافیک دیگر مجتمع شود این مهم ارتقای بزرگی برای دوستداران SLI است; زیرا با اینترفیس قدیمی پی سی آی اکسپرس نسل سومی تنها محدود به مجتمع کردن ۴ کارت گرافیک بودید.

اما تمامی مزایای واسط NVLink را تا سال ۲۰۱۷ فراموش کنید! چون اکنون خیل عظیمی از دستگاهها با رابطهای پی سی آی اکسپرس عرضه میشوند و تغییر ناگهانی غیرممکن است و از طرفی دیگر نسل بعدی پی سی آی اکسپرس هم در راه است که حدوداً دو برابر نسل سوم پهنای باند دارد.

محاسبات ممیزی ۶۴ بیتی با سرعت فزاینده.
یکی از پیشرفتهای معماری پاسکال نسبت به مکسول و کپلر نزدیک شدن نسبت توان محاسبهٔ ممیزی ۶۴ بیتی به ۳۲ بیتی بود; کمی این موضوع را باز میکنیم تا بیشتر درک آن میسر گردد. اکثر کامپیوترهای که جدیداً تولید میشوند پردازندههای با توان ممیزی ۶۴ بیتی دارند. توان محاسبه عددی یکی از مهمترین عاملها در سرعت یک پردازنده است; زیرا هر عملی در تراشهها و پردازندهها به اعداد ختم میشوند و هرچقدر توان ممیزی یک پردازنده بیشتر باشد تعداد عملهای کمتری برای انجام یک فرمان انجام میدهد،. یکی دیگر از کاربرد محاسبات اعشاری با دقت بالا و ۶۴ بیتی در بحث بازی خوری و پردازشهای گرافیکی-ریاضی است. برای مثال در یک بازی بهینه که با آخرین واسطهای برنامهنویسی تطابق دارد و تماماً بهینهشده است برای تعیین دقیق موقعیت اجسام موجود در فضای دو یا سهبعدی، ممیزیهای فیزیکی و تعیین و پردازی اعمال ورودی بهصورت بسیار دقیق، شبیهسازیهای بسیار دقیق و البته شبیهسازیها بسیار پیچیده از اجسام سهبعدی و این دستکارها بهوسیله ممیزی ۶۴ بیتی میتواند رنگ واقعیت بگیرد.
یک عامل دیگر تعیینکننده قدرت یک پردازنده نسبت توان ممیزی ۶۴ بیتی به توان ممیزی اعشاری ۳۲ بیتی است. در معماریهای مکسول و کپلر نسبت این دو عامل در حدود ۱ به ۳ بود; اما در پاسکال این نسبت به حدود ۱ به ۲ افزایشیافته که بسیار عالی است.
انویدیا برای بهینه کردن توان مصرفی دست به تغییراتی در چینش زیر هستههای چندکاره پردازشی خود بانام CUDA زده است; در معماری کپلر در هر گروه SMX تعداد حدودی ۱۹۴ زیر هسته CUDA موجود بود که این تعداد در مکسول به ۱۲۸ عدد میرسید. اما گویی انویدیا متوجه شده است که تعداد گروههای پردازشی SM کمتر در یک پردازنده میتواند باعث استفاده کمتر از انرژی و بهینهتر شدن پردازنده میشود و روند انویدیا از کپلر به مکسول در پاسکال هم مترتب است! در پاسکال (دقیقتر در سوپر تراشهٔ GP 100) تعداد واحدهای SM (که در پاسکال بانام SMP خوانده میشود) به ۵۶ گروه رسیده که هرکدام ۶۴ زیر هستهٔ پردازشی چندوظیفهٔ CUDA دارد. وقتی تعداد واحدهای SM بیشتر میشود میتوان در زمانهای افت بار پردازشی بهتر پردازنده را کنترل کرد. عامل دیگر که در پاسکال ارتقا یافته تعداد GPC ها است; با بیشتر شدن تعداد گروههای SMP تعداد GPC که در معماری پاسکال تعداد آنها به ۶ عدد رسیده که هرکدام تعداد ۱۰ گروه SMP را با مجموع تعداد ۶۴۰ زیر هستههای چندکارهٔ پردازشی CUDA دربرمی گیرد.

هر SMP در GP 100 دارای تعداد ۳۲ بلوک فعال، ۲۰۴۸ خطهای پردازشی فعال، ۶۴ کیلوبایت حافظه اشتراکی و ۲۵۶ کیلوبایت است.
ورود ( HBM 2.0 (High Bandwidth Memory و لیتوگرافی ۱۶ نانومتری FinFET:
انویدیا در تراشه GP 100 توانست با بهرهگیری از مقدار بالایی از ظرفیتهای حافظههای نسل جدید HBM 2.0 پهنای باند تراشهٔ GP 100 را به طرز فزایندهای تا ۷۲۰ گیگابیت بر ثانیه بالا ببرد. حافظههای HBM توانایی تطبیقپذیری زیادی دارند و انویدیا هم از این تطبیقپذیری بالا استفاده کرده و چندین لایه از حافظههای HBM را رویهم قرار میدهد و کل حافظه مجتمع شده را روی یکلایه مادر قرار میدهد. فرکانس مؤثر کاری HBM 2.0 در GP 100 بر روی ۱٫۴ GHz محدودشده است; فرکانس کاری این حافظه میتوانست بیشتر از اینها هم باشد اما انویدیا بنا به شرایط توان مصرفی پردازنده و باسهای تراشه تصمیم گرفت روی همین سرعت HBM 2.0 بماند; درست مانند تراشههای استفادهشده در کارتهای R9 Nano و R9 Fury X از ایام دی.

در آخر انویدیا از لیتوگرافی ۱۴ نانومتری شرکت TSMC با فناوری سه بعدی ترانزیستور FinFET استفاده کرده تا توان مصرفی تراشه اصلی را تا ۳۰% کاهش دهد و در عوض تا ۲۰ درصد به بهبود بازده تراشه کمک کند. در ادامه جدولهای مقایسه پاسکال با نسلهای قبلش را می میبینید.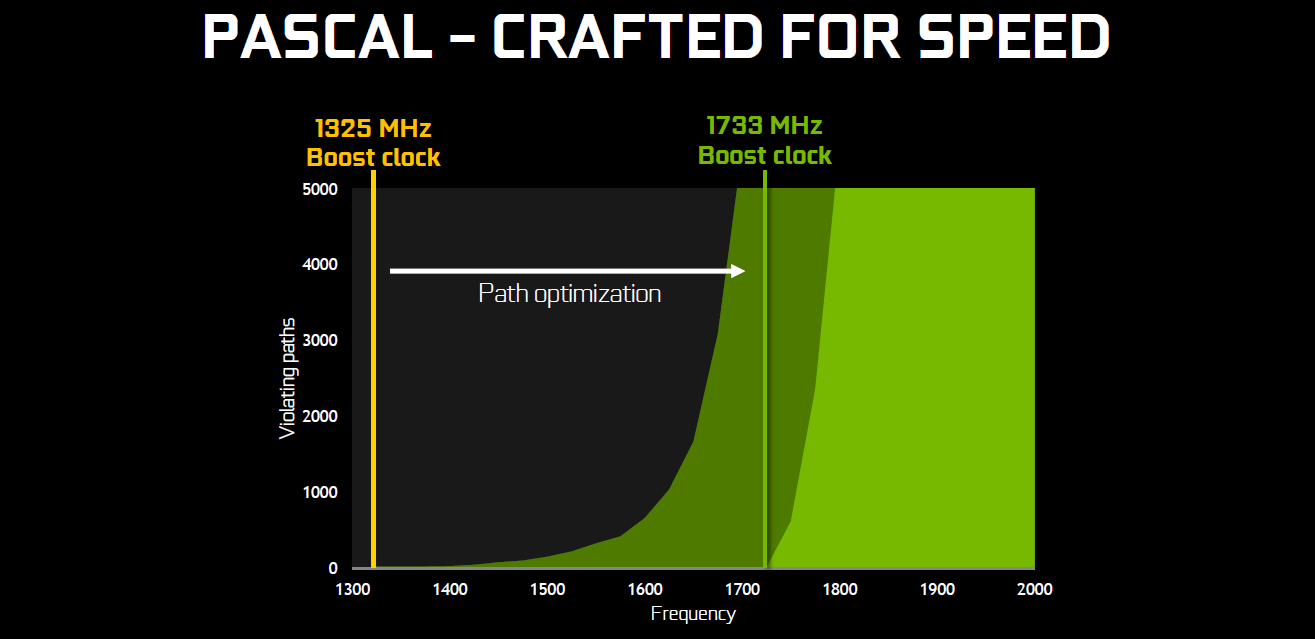
صفحه دوم; گریزی بر معماری پاسکال (در حال خواندن آن هستید)
صفحه سوم; ویژگیهای جدید GTX1060 نسبت به GeForce GTX 960.
صفحه چهارم; بررسی قلب تپنده GTX 1060، سیلیکون GP 106.
صفحه پنجم; بررسی اتصالات، پورتها، چیپهای واپایشگر، توان مصرفی دما و صدای تولیدی.
صفحه هفتم; بنچمارکها و نتایج بنچمارک بازی.






جای یک همچین برسی مفصلی در سایت های تکنولوژی ایران خالی بود! خوشحالم در حالی که سایت ها پر شده از مطالب تکراری در مورد آیفون و سامسونگ، مقاله ای به این مفیدی و البته تخصصی خوندم! امیدوارم بیشتر از این دست مطالب مفید شاهد باشیم.
با سپاس فراوان از نویسنده مطلب :good: